开始使用Logstash
这个章节将指导你安装Logstash,并通过设定使其能正常工作。在学习完如何存储第一个事件之后,您将创建一个更高级的管道,由Apache 的web日志作为INPUT,解析日志并将解析后的日志存储到一个Elasticsearch集群中。然后你将学习到如何结合输入输出插件将不同来源的日志进行统一。
这个章节包含以下内容:
安装Logstash
使用下面的命令检查你的Java版本:
java -version如果系统中安装了Java,则会输出类似下面的信息:
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)在某些Linux系统中,安装之前你可能还需要设定JAVA_HOME环境变量,特别是你使用的是二进制安装方式。Logstash在安装过程中需要Java环境来安装正确的启动方法(SYSV init 脚本,开机自启,systemd)。如果Logstash无法找到正确的JAVA_HOME变量,你将会收到一个错误信息,并且Logstash将不能正确的启动。
Install from a Downloaded Binary(二进制安装)
下载适用于你的环境的安装文件并解压。注意解压目录名中不要包含(:)符号。(目录名中不要有冒号)
NOTE:这些包可以在Elastic的许可下免费试用。其中包含开源和免费的商业特性和可选的付费商业特性。开始为期30天的付费全功能版本。更多信息参考“订阅”页面。
或者,你可以下载一个
oss包,包含Apache2.0许可下的所有特性。
在支持的Linux发行版,你也可以使用包管理器来安装Logstash。
Installing from Package Repositories
我们同时也提供了基于YUM和APT包管理器的源。注意我们只提供了二进制包,而不提供源码包。因为这是计划的一部分。(因为Logstash把包作为构建的一部分进行构建。原文:the packages are created as part of the Logstash build.)
我们已经将Logstash源按版本拆分为单独的URL,以避免大版本升级可能带来的意外情况。对于所有6.x.y版本,使用6.x作为版本号。
我们使用PGP key D88E42B4,下面的指纹信息来签名我们的包,许可来自 https://pgp.mit.edu
4609 5ACC 8548 582C 1A26 99A9 D27D 666C D88E 42B4APT
下载并安装以下公钥:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -在Debian上你可能还需要安装apt-transport-https包才能继续:
sudo apt-get install apt-transport-https将源文件保存在/etc/apt/sources.list.d/elastic-6.x.list:
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.listWARNING:使用如上的
echo命令来添加Logstash源,不要使用add-apt-repository否则系统会添加一个deb-src源,但我们并没有对应的包。如果你有一个deb-src源,你会看到如下的错误信息:Unable to find expected entry 'main/source/Sources' in Release file (Wrong sources.list entry or malformed file)这种情况只需要从
/etc/apt/sources.list文件中删除deb-src源即可。
执行sudo apt-get update准备好之后使用下面的明星安装:
sudo apt-get update && sudo apt-get install logstash查看运行Logstash查看如何以系统服务管理Logstash。
YUM
下载并安装公钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch在/etc/yum.repos.d/目录下创建一个.repo结尾的文件,内容如下:
[logstash-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md准备好之后运行下面的命令来安装:
sudo yum install logstashWARNING:在RPM v3或更低版本源不再支持,如CentOS5。
查看运行Logstash查看如何以系统服务管理Logstash。
Docker
在Elastic Docker仓库,已经提供了可以作为容器运行的Logstash镜像。
查看Running Logstash on Docker来查看如何以容器的方式运行和配置Logstash。
储存你的第一个事件
首先,让我们运行一个最基本的Logstash管道来确保你的Logstash运行正常。
一个Logstash管道有两个必须的组件,input和output,除此之外还有一个可选的组件filter。input插件将数据从源读入,filter插件按照你的定义处理数据,最后通过output插件写入到目的地。
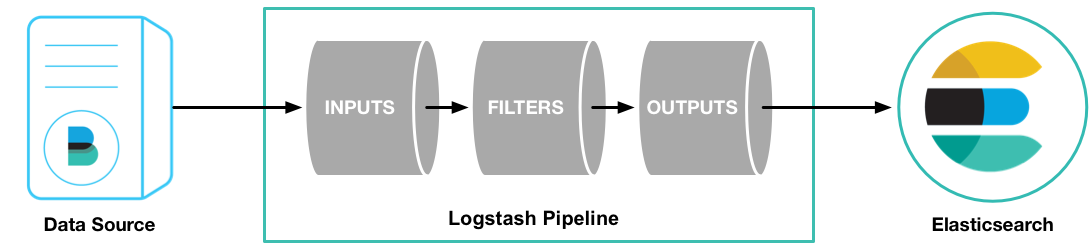
参照如下示例来运行最基本的Logstash管道来检查Logstash的安装:
cd logstash-6.4.3
bin/logstash -e 'input { stdin { } } output { stdout {} }'NOTE:
bin目录的位置因平台而异,查看Directory layout来找到你系统上的bin/logstash。(如果使用yum进行安装,通常尝试直接执行logstash -e 'input { stdin { } } output { stdout {} }',如果使用二进制安装,则bin目录位于你解压的目录下。)
使用-e选项允许你在命令行快速配置而不必修改配置文件,这个示例将从stdin来读取你的输入,并将输出以结构化的方式输出至stdout。(就是从命令行读取,在终端上输出。)
Logstash启动之后你可以在屏幕上看到”Pipeline main started”,输入hello world并回车:
hello world
2013-11-21T01:22:14.405+0000 0.0.0.0 hello worldLogstash添加了时间标签和IP地址在输出的信息上。如果要退出在命令行运行的Logstash可以按CTRL+D组合键。
恭喜!你已经创建了一个最基本的Logstash管道,接下来,我们学习如何创建更实用的管道。
通过Logstash解析日志
上面的示例中你已经创建了一个最基本的Logstash管道来测试你的Logstash,在实际的情形中,Logstash通常面临着更加复杂的场景:一个或多个input、filter和output插件。
本段,你将创建一个Logstash管道,使用Filebeat采集的Apache日志作为input,从日志中解析特殊字段,然后将解析后的数据写入一个Elasticsearch集群。这次你将定义一个配置文件,而不是在命令行中设定。
在这里下载示例数据,以便我们可以开始。
配置Filebeat来发送日志到Logstash
在创建Logstash管道之前,你需要配置Filebeat来将日志发送到Logstash。Filebeat是一个轻量的、友好的日志收集客户端,它从你服务器上的文件中收集日志,并转发到Logstash以进行实时处理。Filebeat是为可靠性和低延迟设计的。Filebeat可以在你的主机上占用更少的资源,使用Beats input插件将让你的Logstash实例的资源使用降到最低。
NOTE:在一个典型的使用场景中,Filebeat运行在和Logstash不同的单独的主机上,在这个演示的实例中我们将Logstash和Filebeat运行在同一台主机上。
默认情况下Logstash会安装Beats input插件。Beats input插件允许Logstash接收来自Elastic Beats框架的事件,这意味着任何基于Beats框架的Beat written如Packetbeat和Metricbeta都可以给Logstash发送事件。
要在你的数据源主机上安装适合的Filebeat,可以在这里下载。你也可以在这里查看Beats的安装文档。
安装完成之后你需要进行一些配置。在你的安装目录中找到并打开filebeat.yml文件,然后使用下面的内容替换其中的内容。确保paths指向下载的测试用的Apache日志文件logstash-tutorial.log。
filebeat.prospectors:
- type: log
paths:
- /path/to/file/logstash-tutorial.log ①
output.logstash:
hosts: ["localhost:5044"]① 文件或目录的绝对路径。(原文:Absolute path to the file or files that Filebeat processes.)
保存更改。
为了更加简单,这里不用配置TLS/SSL。在生产中,通常需要配置这些。
在数据源的主机上执行下面的命令来运行Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"NOTE:如果你使用root运行Filebeat,你需要手动更改配置文件的权限(参考:Config File OwnerShip and Permissions)。
Filebeat使用5044进行连接,在Logstash启动Beats插件之前,Filebeat不会收到任何响应,所以此时你看到的任何连接此端口失败的消息都是正常的。
配置Logstash使用Filebeat作为输入
接下来,你将创建一个Logstash管道使用Beats input插件接收来自Beats的事件。
下面是一个配置文件的框架:
# The # character at the beginning of a line indicates a comment. Use
# comments to describe your configuration.
input {
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
}这个框架没有任何功能,因为在input 和 output 没有定义任何选项。
在Logstash的home目录下创建一个文件,名为first-pipeline.conf,将上述内容复制进去。(Logstash的home目录应该是指Logstash安装目录。)
接下来,在first-pipeline.conf文件中的input配置段添加以下内容来使用Beats input 插件:
beats {
port => "5044"
}你可以稍后配置Elasticsearch。现在,将下面的内容填入到配置文件中的output配置段。其作用是在你运行Logstash的时候将输出结果输出到stdout。
stdout { codec => rubydebug }完成之后first-pipeline.conf的内容应该如下:
input {
beats {
port => "5044"
}
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
stdout { codec => rubydebug }
}你可以使用下面的命令来检查你的配置文件:
bin/logstash -f first-pipeline.conf --config.test_and_exit--config.test_and_exit选项会分析你的配置文件并将其中的错误输出。
如果配置文件通过了检查,你可以使用下面的命令来启动Logstash:
bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic选项可以让Logstash在你修改配置文件之后重载而不必重新启动。
当Logstash启动之后,你可能会看到一到多条关于忽略pipelines.yml文件的警告信息。你可以忽略这些警告。pipelines.yml文件是用来在一个Logstash示例中运行多个管道使用的。在这个演示的示例中,你只运行一个管道。
如果运行正确你应该能在屏幕上看到如下的输出信息:
{
"@timestamp" => 2017-11-09T01:44:20.071Z,
"offset" => 325,
"@version" => "1",
"beat" => {
"name" => "My-MacBook-Pro.local",
"hostname" => "My-MacBook-Pro.local",
"version" => "6.0.0"
},
"host" => "My-MacBook-Pro.local",
"prospector" => {
"type" => "log"
},
"source" => "/path/to/file/logstash-tutorial.log",
"message" => "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \"GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1\" 200 203023 \"http://semicomplete.com/presentations/logstash-monitorama-2013/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}
...使用Grok Filter插件解析Web Logs
现在你已经有了一个正常工作的从Filebeat读取日志的管道。但是,你知道日志的格式并不理想。你希望解析这些日志文件中的特殊字段。为了实现这个,你需要用到grok filter插件。
Grok filter插件是少数Logstash默认可以使用的插件之一。更多关于管理Logstash插件的信息,参考reference documentation。
Grok插件可以将非结构化的数据转换为高质量的结构化数据。
由于grok插件从传入的日志中进行匹配查找,所以需要你根据自己感兴趣的数据来配置插件。如典型的Web服务日志如下:
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png
HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel
Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"很容易辨认出最开始的是IP地址,方括号中的是时间标签。对于Apache日志你可以使用%{COMBINEDAPACHELOG}来将数据解析成如下结构。
| Information | Field Name |
|---|---|
| IP Address | clientip |
| User ID | ident |
| User Authentication | auth |
| timestamp | timestamp |
| HTTP Verb | verb |
| Request body | request |
| HTTP Version | httpversion |
| HTTP Status Code | response |
| Bytes served | bytes |
| Referrer URL | referrer |
| User agent | agent |
TIP:如果在构建Grok匹配模式上需要帮助,你可以使用Grok Debugger。Grok Debugger是基本许可下的X-Pack的一个附加特性,可以免费使用。
编辑first-pipeline.conf文件并使用下面的内容替换其中的filter字段:
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}完成之后first-pipeline.conf中的内容应该如下:
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}保存更改,由于已经开启了自动重载配置文件,因此你不必重新启动Logstash来使配置生效。但是你需要让Filebeat强制从头开始读取日志文件。在对应的终端上使用Ctrl+C组合键来关闭Filebeat。然后删除Filebeat的registry文件,命令如下:
sudo rm data/registryFilebeat的registry文件保存了它读取的文件的状态,删除之后可以强制让Filebeat重新从头读取这些文件。
然后使用下面的命令重启Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"你可能需要等待一小会儿如果Filebeat等待Logstash重读配置文件的话。
在Logstash完成重读并匹配完成之后,事件将用JSON的格式表示如下:
{
"request" => "/presentations/logstash-monitorama-2013/images/kibana-search.png",
"agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"offset" => 325,
"auth" => "-",
"ident" => "-",
"verb" => "GET",
"prospector" => {
"type" => "log"
},
"source" => "/path/to/file/logstash-tutorial.log",
"message" => "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \"GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1\" 200 203023 \"http://semicomplete.com/presentations/logstash-monitorama-2013/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://semicomplete.com/presentations/logstash-monitorama-2013/\"",
"@timestamp" => 2017-11-09T02:51:12.416Z,
"response" => "200",
"bytes" => "203023",
"clientip" => "83.149.9.216",
"@version" => "1",
"beat" => {
"name" => "My-MacBook-Pro.local",
"hostname" => "My-MacBook-Pro.local",
"version" => "6.0.0"
},
"host" => "My-MacBook-Pro.local",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:13:42 +0000"
}需要注意的是原本的消息内容会被保留,但消息同时也会被分割成不同的字段。
使用GeoIP插件丰富你的数据
除了解析日志以便于搜索,filter插件还可以从现有的数据中进行扩展。举个例子,geoip插件可以从IP地址获取物理位置信息并将其添加到日志中。
在first-pipeline.conf文件的filter字段中添加以下内容来使用geoipfilter插件:
geoip {
source => "clientip"
}geoip插件的配置需要你指定包含要查找的IP地址的源字段的名称。在示例中,clientip字段包含IP地址。
因为filter是按照顺序进行解析,所以配置文件中的geoip字段要在grok字段之后且这两个字段都要在filter字段中
当你做完之后,first-pipeline.conf文件中的内容应该如下:
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}保存设置,和之前一样强制停止Filebeat然后删除registry文件,然后使用下面的命令重启Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"注意事件中现在已经包含了物理位置信息:
{
"request" => "/presentations/logstash-monitorama-2013/images/kibana-search.png",
"agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"geoip" => {
"timezone" => "Europe/Moscow",
"ip" => "83.149.9.216",
"latitude" => 55.7485,
"continent_code" => "EU",
"city_name" => "Moscow",
"country_name" => "Russia",
"country_code2" => "RU",
"country_code3" => "RU",
"region_name" => "Moscow",
"location" => {
"lon" => 37.6184,
"lat" => 55.7485
},
"postal_code" => "101194",
"region_code" => "MOW",
"longitude" => 37.6184
},
...将你的数据索引到Elasticsearch
现在web日志已经按照字段进行分割,你已经准备好将数据写入Elasticsearch。
TIP:你可以在你自己的硬件上运行Elasticsearch,也可以使用我们的Elastic云上的Elasticsearch主机服务。AWS和GCP都提供了Elasticsearch服务。免费试用一下。
Logstash可以将数据索引到Elasticsearch集群。编辑first-pipeline.conf文件中的output字段,内容如下:
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}这个配置中,Logstash使用HTTP协议连接Elasticsearch。上面的示例中Logstash和Elasticsearch运行在相同 的实例中。你也可以指定一个远程Elasticsearch实例通过配置hosts如:hosts => ["es-machine:9200"]。
到这里,你的first-pipeline.conf包含input,filter,和output配置,没问题的话,应该是下面这样:
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}保存配置,像之前一样强制中止Filebeat,删除registry文件,然后使用下面的命令重启Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"测试你的管道
现在你的Logstash已经将数据存储到Elasticsearch集群中,你可以在Elasticsearch集群中进行查询。
尝试在Elasticsearch中查询grokfilter插件创建的字段。用YYYY.MM.DD格式的当前时间替换下面的$DATE:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=response=200'NOTE:数据使用的索引名称基于UTC时间,并非Logstash运行的当地时间。如果查询返回
index_not_found_exception,确保logstash-$DATE对应的名字是正确的索引名。可以使用这个查询指令来查看所有可用的索引:curl 'localhost:9200/_cat/indices?v'
应该会返回多个命中结果。如下:
{
"took": 50,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 98,
"max_score": 2.793642,
"hits": [
{
"_index": "logstash-2017.11.09",
"_type": "doc",
"_id": "3IzDnl8BW52sR0fx5wdV",
"_score": 2.793642,
"_source": {
"request": "/presentations/logstash-monitorama-2013/images/frontend-response-codes.png",
"agent": """"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"""",
"geoip": {
"timezone": "Europe/Moscow",
"ip": "83.149.9.216",
"latitude": 55.7485,
"continent_code": "EU",
"city_name": "Moscow",
"country_name": "Russia",
"country_code2": "RU",
"country_code3": "RU",
"region_name": "Moscow",
"location": {
"lon": 37.6184,
"lat": 55.7485
},
"postal_code": "101194",
"region_code": "MOW",
"longitude": 37.6184
},
"offset": 2932,
"auth": "-",
"ident": "-",
"verb": "GET",
"prospector": {
"type": "log"
},
"source": "/path/to/file/logstash-tutorial.log",
"message": """83.149.9.216 - - [04/Jan/2015:05:13:45 +0000] "GET /presentations/logstash-monitorama-2013/images/frontend-response-codes.png HTTP/1.1" 200 52878 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"""",
"tags": [
"beats_input_codec_plain_applied"
],
"referrer": """"http://semicomplete.com/presentations/logstash-monitorama-2013/"""",
"@timestamp": "2017-11-09T03:11:35.304Z",
"response": "200",
"bytes": "52878",
"clientip": "83.149.9.216",
"@version": "1",
"beat": {
"name": "My-MacBook-Pro.local",
"hostname": "My-MacBook-Pro.local",
"version": "6.0.0"
},
"host": "My-MacBook-Pro.local",
"httpversion": "1.1",
"timestamp": "04/Jan/2015:05:13:45 +0000"
}
},
...尝试使用从IP地址派生出的地理信息来查询。使用当前时间替换$DATE,用YYYY.MM.DD格式的时间:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=geoip.city_name=Buffalo'有些日志来自Buffalo,所以应该会返回下面的结果:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 2.6390574,
"hits": [
{
"_index": "logstash-2017.11.09",
"_type": "doc",
"_id": "L4zDnl8BW52sR0fx5whY",
"_score": 2.6390574,
"_source": {
"request": "/blog/geekery/disabling-battery-in-ubuntu-vms.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+semicomplete%2Fmain+%28semicomplete.com+-+Jordan+Sissel%29",
"agent": """"Tiny Tiny RSS/1.11 (http://tt-rss.org/)"""",
"geoip": {
"timezone": "America/New_York",
"ip": "198.46.149.143",
"latitude": 42.8864,
"continent_code": "NA",
"city_name": "Buffalo",
"country_name": "United States",
"country_code2": "US",
"dma_code": 514,
"country_code3": "US",
"region_name": "New York",
"location": {
"lon": -78.8781,
"lat": 42.8864
},
"postal_code": "14202",
"region_code": "NY",
"longitude": -78.8781
},
"offset": 22795,
"auth": "-",
"ident": "-",
"verb": "GET",
"prospector": {
"type": "log"
},
"source": "/path/to/file/logstash-tutorial.log",
"message": """198.46.149.143 - - [04/Jan/2015:05:29:13 +0000] "GET /blog/geekery/disabling-battery-in-ubuntu-vms.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+semicomplete%2Fmain+%28semicomplete.com+-+Jordan+Sissel%29 HTTP/1.1" 200 9316 "-" "Tiny Tiny RSS/1.11 (http://tt-rss.org/)"""",
"tags": [
"beats_input_codec_plain_applied"
],
"referrer": """"-"""",
"@timestamp": "2017-11-09T03:11:35.321Z",
"response": "200",
"bytes": "9316",
"clientip": "198.46.149.143",
"@version": "1",
"beat": {
"name": "My-MacBook-Pro.local",
"hostname": "My-MacBook-Pro.local",
"version": "6.0.0"
},
"host": "My-MacBook-Pro.local",
"httpversion": "1.1",
"timestamp": "04/Jan/2015:05:29:13 +0000"
}
},
...如果你使用Kibana来可视化你的数据,你可以在Kibana中查看你通过Filebeat获取的数据:
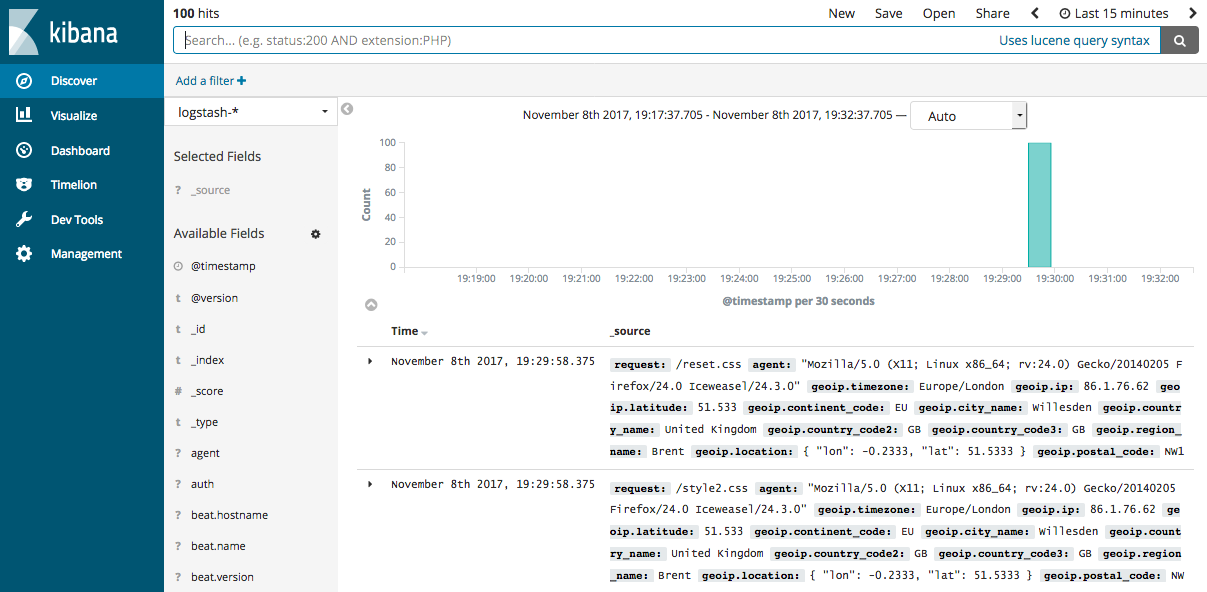
查看Filebeat getting started docs获取关于在Kibana中加载Filebeat索引的信息。
你已经成功的创建了一个Logstash管道,通过Filebeat采集Apache日志作为input,分析其中的特殊字段,然后将分析后的字段写入到Elasticsearch集群中。接下来,即将学习如何创建一个管道同时使用多个input和output插件。
多个输入和输出插件的混合使用
通常你管理的信息会来自于不同的地方,你的用例也可能要求将数据存储到不同的目的地。你的Logstash管道可以使用多个input和output插件来满足这些需求。
在本章节,你将创建一个Logstash管道同时从Twitter和Filebeat客户端获取信息,然后将这些信息存储到Elasticsearch集群的同时直接写入文件。
从Twitter读取
要添加一个Twitter输入,你可以使用twitterinput插件。要配置这个插件,你需要下面几条信息:
- 一个用来唯一标示您的Twitter应用程序的用户密钥。
- 一个用来充当Twitter应用密码的秘密。(不知道怎么翻译这一句,原文:A consumer secret, which serves as the password for your Twitter app.)
- 要在传入的Feed中搜索的一个或多个关键字。在这个例子中使用“Cloud”作为关键字,你可以自定义你想要搜索的任何东西。
- 一个认证令牌,使此应用可以识别一个Twitter帐号。
- 一个认证令牌秘密,用作Twitter帐号密码。(原文:An oauth token secret, which serves as the password of the Twitter account.)
访问https://dev.twitter.com/apps来设置Twitter帐号和生成你的用户密钥和秘密,以及你的认证令牌和秘密。如果你不确定如何生成这些信息,查看twitterinput插件的文档来获取更多信息。
注:这个Twitter app似乎有些类似在微信或者其他什么开发平台申请的一个自己创建的应用,并非Twitter应用本身,至于那什么用户密钥,秘密,认证令牌什么的应该于此有关。鉴于Twitter属于404网站,不好研究。自己感受下吧。
和之前一样创建一个配置文件(命名为second-pipeline.conf)并且使用同样的配置框架。如果你懒,还可以复制一份刚才的,只是运行的时候确保使用的是正确的配置文件。
将下面的内容填写到input配置段中,并根据自己的情况替换其中的内容:
twitter {
consumer_key => "enter_your_consumer_key_here"
consumer_secret => "enter_your_secret_here"
keywords => ["cloud"]
oauth_token => "enter_your_access_token_here"
oauth_token_secret => "enter_your_access_token_secret_here"
}配置Filebeat将日志发送到Logstash
正如之前了解的,Filebeat是一个轻量级,资源友好的工具用来从服务器文件上收集日志并将其转发给Logstash实例进行处理。
在安装Filebeat之后,你需要进行一些配置。在本地安装目录中打开filebeat.yml文件,并用下面的内容替换其中内容。确保path指向你的系统日志:
filebeat.prospectors:
- type: log
paths:
- /var/log/*.log ①
fields:
type: syslog ②
output.logstash:
hosts: ["localhost:5044"]① 指定一个或多个文件的绝对路径
② 向事件添加一个type字段,值为syslog
保存设置。
同样,为了简单,这里你不需要配置TLS/SSL,但在生产中可能并非如此。
通过向second-pipeline.conf文件的input配置段添加以下信息来使用Filebeat input 插件。
beats {
port => "5044"
}把Logstash数据写入文件
使用fileoutput插件,可以配置你的Logstash管道直接将数据写入文件。
通过向second-pipeline.conf文件的output配置段添加如下信息来使用fileoutput插件:
file {
path => "/path/to/target/file"
}写入多个Elasticsearch节点
写入多个Elasticsearch节点可以减轻特定节点的负载,并且可以在主节点不可用时提供冗余入口。
要配置此功能,在second-pipeline.conf文件的output配置段中添加如下信息:
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
}在hosts行配置三个非主节点的Elasticsearch节点IP地址。当hosts中配置多个IP地址的时候,Logstash会在地址列表中进行负载均衡,如果Elasticsearch使用的是默认的9200端口,你可以在上面的配置中省略它。
测试
通过上面的配置,second-pipeline.conf内容应该如下:
input {
twitter {
consumer_key => "enter_your_consumer_key_here"
consumer_secret => "enter_your_secret_here"
keywords => ["cloud"]
oauth_token => "enter_your_access_token_here"
oauth_token_secret => "enter_your_access_token_secret_here"
}
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
file {
path => "/path/to/target/file"
}
}Logstash现在同时从你配置的Twitter feed和Filebeat中接收数据,将数据存储到Elasticsearch集群的三个节点的同时将数据写入到一个文件。
在数据源主机上使用下面的命令启动Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"Logstash启动之前,Filebeat会收到连接5044失败的错误信息,这是正常的。
要验证你的配置,使用下面的命令:
bin/logstash -f second-pipeline.conf --config.test_and_exit--config.test_and_exit选项检查你的配置文件并向你报告其中的错误。当配置文件通过检查之后,使用下面的命令启动Logstash:
bin/logstash -f second-pipeline.conf使用grep工具在目标文件中搜索来验证是否存在信息:
grep syslog /path/to/target/file然后运行一个Elasticsearch查询来搜索同样的内容:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=fields.type:syslog'用当前的时间替换其中的$DATE,时间使用YYYY.MM.DD格式。
使用下面的查询语句从Twitter feed,中查询数据:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=fields.type:syslog'同样的,记得用当前的时间替换其中的$DATE变量,格式依然是YYYY.MM.DD
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!